Vorbis: End-to-end multimodal speech recognition
Automatic speech recognition (ASR) has been an intensely studied topic in the last decades, its research leading to a wide range of applications (e.g., smart home assistants or automatic video transcription). However, ASR systems are still prone to errors when the recording conditions are difficult (noise, reverberations, accents) or when training data is scarce (low-resource languages). A way of improving an ASR system is to use extra information. In this project we aim to leverage the visual context, which is provided by images that are recorded at the same time the command is uttered. Cases when the two modalities (audio and vision) coexist include voice-based robot navigation or video-based content (documentaries, news, instructional videos). The objectives of the project center around building such a multimodal speech recognition system and empirically showing that it indeed outperforms an audio-only ASR system. In order to obtain such a system we plan to make use of one of the ingredients of deep learning, namely end-to-end learning. Developing an end-to-end multimodal system will allow us to jointly optimize for the final objective function and will to facilitate various model combinations. A successful project will enable other scientific directions, such as automatic video summarization or semi-supervised multimodal learning.
This project is supported by the Romanian National Authority for Scientific Research and Innovation, UEFISCDI:
Project number: PN-III-P1-1.1-PD-2019-0918
Contract number: PD 97 / 2020
Period: 2020-09-01 – 2022-08-31
Research fields: machine learning, statistical data processing and applications using signal processing (e.g., speech, image, video)
Objectives
The goal of the project is to improve the generated transcriptions of an automatic speech recognition system by incorporating visual information. Towards this goal, we have set three objectives:- O1. Automatic speech recognition using end-to-end learning
- O2. Image understanding using end-to-end learning
- O3. Multimodal end-to-end speech recognition by fusing the two types of end-to-end architectures (O1 and O2)
Deliverables
- D1. State of the art survey
- D2. End-to-end automatic speech recognition system
- D3. End-to-end image understanding system
- D4. End-to-end multimodal system for automatic speech recognition
- D5. Two conference articles and a journal article
Summary of results
In this project, we have built state-of-the-art methods for multimodal speech recognition. Compared to traditional automatic speech recognition (ASR), which generates transcriptions based solely on audio input, the multimodal setting involves using an additional input corresponding to the visual stream (e.g., image or video). The main motivation of this setup is that the visual information is often associated with audio (as encountered in instructional videos, documentaries, movies) and it can help disambiguate the audio recording, consequently, producing more accurate transcriptions.
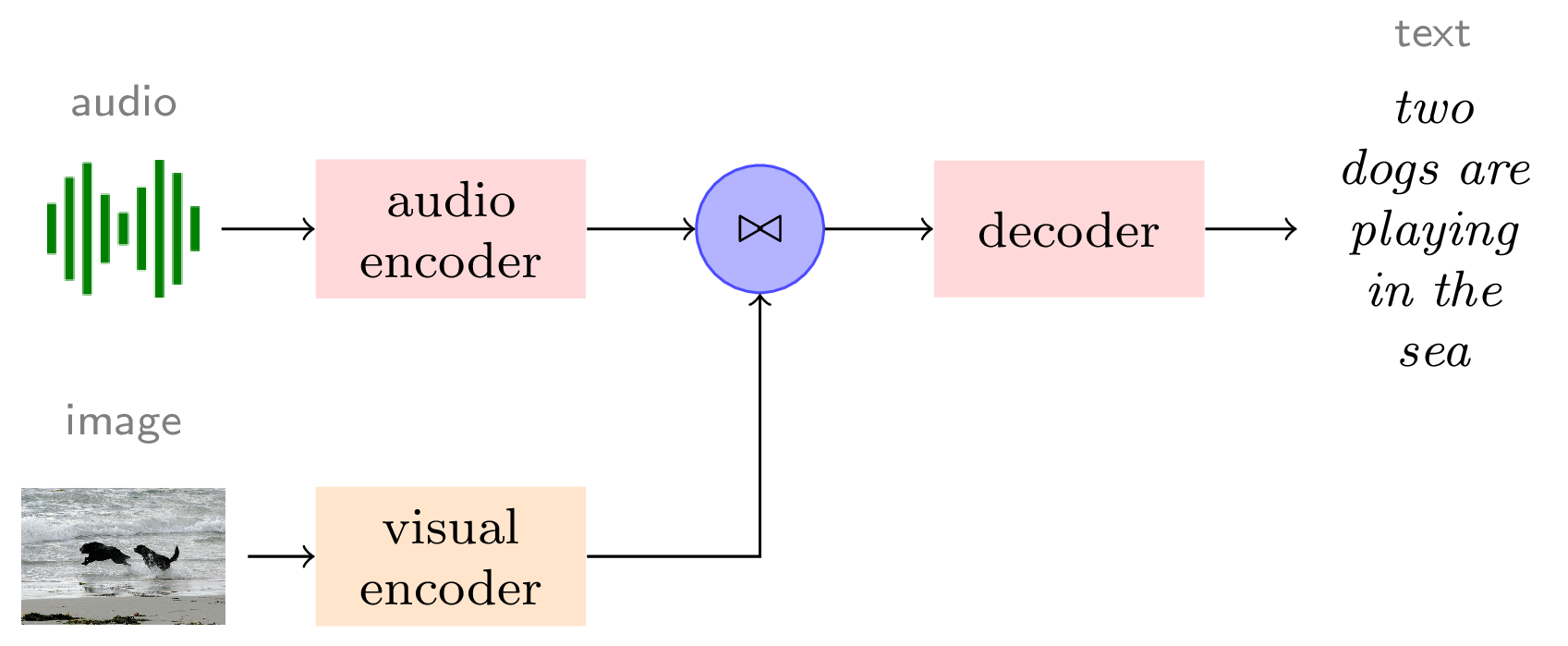
Our main approach employs a Transformer ASR architecture as a baseline system in which we inject visual information through a ResNet image encoder. In contrast to the previous methods, we leverage pretrained representations for both the speech and visual channels, which are then finetuned in an end-to-end manner. We further explore two fusion techniques for the two input channels. Our approach leads to substantial improvements over the state of the art on two standard multimodal datasets: Flickr8K and How2. The ablation studies provide important insights on the role of using speech augmentation before training the multimodal network and the individual contribution of finetuning the various components of the system. Below we present some qualitative results of our approach. While we find it remarkable that the multimodal setting still improves over a strong unimodal baseline, there are still open questions regarding how the multimodal system is using the visual information.
 |
 |
 |
| r · mix it up really good because that egg white is thick it’s really thick | r · and spalting is nothing more than the natural decay process that wood goes through | r · so we can either take the fiber wire or use the shotgun or use the pistol that we picked up |
| u · mix it up really good because that eight white is thick it’s really thick | u · and spalting is nothing more than the natural decay process that would goes through | u · so we can either take the fiber wire or use the shock on or use the pistol that we picked up |
| m · mix it up really good because that egg white is thick it’s really thick | m · and spalting is nothing more than the natural decay process that wood goes through | m · so we can either take the fiber wire or use the shotgun or use the pistol that we picked up |
Publications
- D. Oneață and H. Cucu. Multimodal speech recognition for unmanned aerial vehicles. Computers & Electrical Engineering, 90:106943, 2021.
- D. Oneață, A. Stan, and H. Cucu. Speaker disentanglement in video-to-speech conversion. In 29th European Signal Processing Conference, 2021.
- A. Caranica, D. Oneață, H. Cucu, and C. Burileanu. Confidence estimation for lattice-based and lattice-free automatic speech recognition. UPB Scientific Bulletin, Series C: Electrical Engineering and Computer Science, 83(3):155–170, 2021.
- K. Olaleye, D. Oneață, and H. Kamper. Keyword localisation in untranscribed speech using visually grounded speech models. IEEE Journal of Selected Topics in Signal Processing, 2022.
- D. Oneață, B. Lőrincz, A. Stan, and H. Cucu. FlexLip: A controllable text-to-lip system. Sensors, 22(11), 2022.
- D. Oneață and H. Cucu. Improving multimodal speech recognition by data augmentation and speech representations. In IEEE Computer Vision and Pattern Recognition Workshops. 2022.

